写在开篇
Git作为目前使用最为广泛的分布式版本控制系统,其设计思路和使用实战都值得我们去了解和掌握。这篇blog主要记录了我学习Git的过程,以及在学习过程中一些心得体会,同时将目前学到的内容如何在实战中应用做一个简单的介绍,帮助从未接触过版本控制,或者一直在使用Subversion等集中式版本控制系统的同学快速上手过渡至Git。
参考资料
文章主要参考资料:
- Git详解:对Git的工作机制做了深入的分析
- Git参考手册:中文版的使用手册
- Git使用积累
- Why is Git better than Subversion?
操作环境
文章中会涉及一些实际操作,操作系统为macos,git工作目录为临时新建的目录,想要实操的同学可以在任意文件夹执行git init命令后跟随实操。
Git学习
什么是Git?
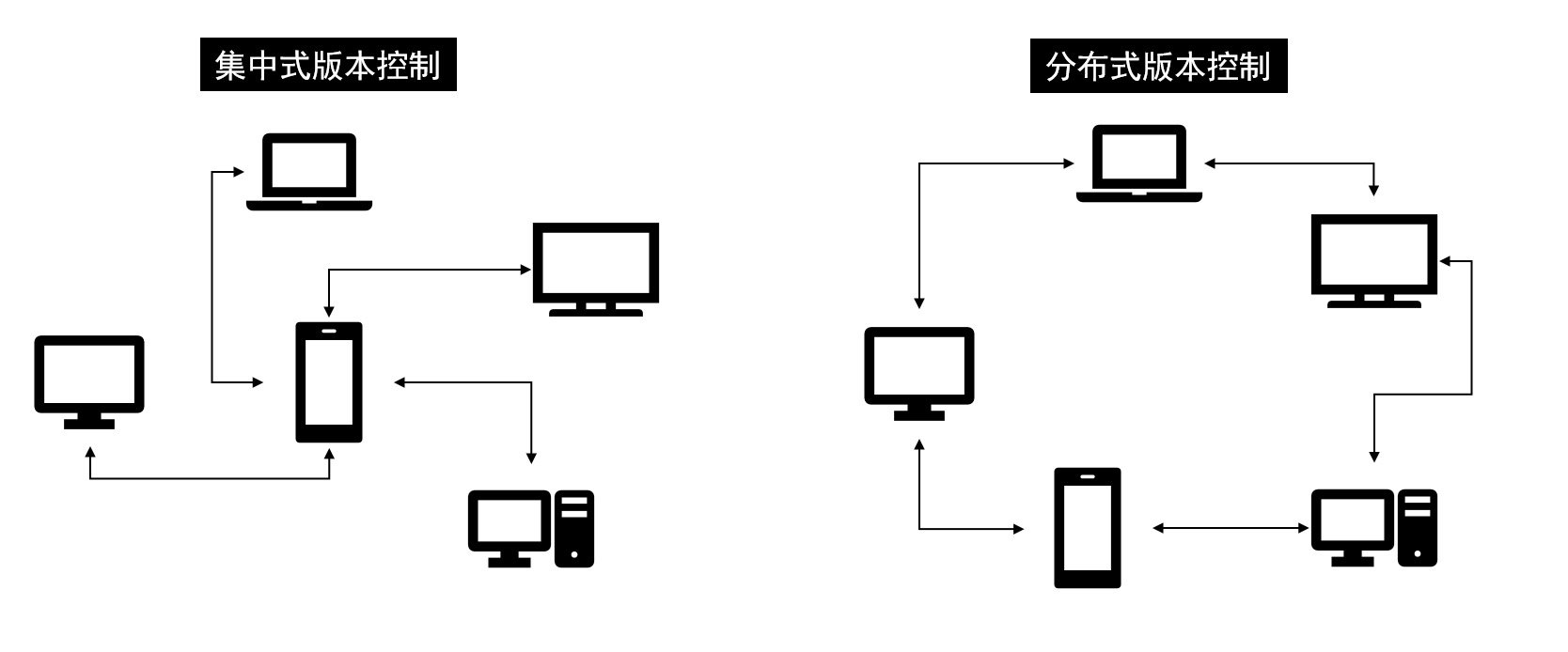
如开篇所说,Git是一个分布式版本控制系统,与普通的SVN和CVS等集中式版本控制系统一样,同样是用于进行文件仓库的版本控制。不同的地方在于,集中式版本控制系统,将文件仓库放置于一个中央服务器上,所有的文件版本记录都仅保存在中央仓库上,当你想在客户端切换文件的版本时,需要请求中央仓库以获取特定版本的信息;而分布式版本控制系统,将文件仓库放置于每个用户的本地,每个用户的文件仓库之间可以通过多种协议交换版本记录,当你想切换文件的版本时,可以直接在本地进行版本切换。下图说明了二者的区别。
Git的工作原理
1. Git内容寻址文件系统
Git版本控制的核心是一个基于键值对搜索的内容寻址文件系统,使用内容的SHA-1哈希值作为内容的键值,通过管理键值达到管理文件的目的。当然Git除了这一核心功能外,为了达成分布式的高效性,还有一些传输协议,内容压缩,垃圾清理等方面的功能,这里不做讨论。我们把视角关注于Git的版本控制,来看一下Git是如何完成这项任务的。
2. Git主要对象类型及核心设计思路
Git版本控制的核心概念包括:引用,缓冲区和三种特殊的对象。三种特殊的对象具体来说为:文件内容(blob),树(tree),提交(commit)。我们先简单看一下Git的目录结构
1 | ll .git |
HEAD文件、index文件、objects目录、refs目录是我们这里需要重点关注的。其中,HEAD属于一种特殊的引用,其余所有引用在未压缩的情况下都存储于refs目录下。index文件为一个二进制文件,即为缓冲区,记录了工作目录下所有需要跟踪的文件的索引和状态(记住!!这里是索引,不记录实际存储对象)。三种特殊的对象(blob,tree,commit)在未压缩的情况下存储于objects目录下。我们先从最基础的Git仓库的存储单元说起:blob对象。
blob对象
blob对象实际就是通过zlib压缩的文件快照(同时Git还未此文件增加了一个文件头)。Git通过将blob对象存储至Git仓库中来保存一个文件的历史版本。实际上我们可以通过的Git的hash-object命令创建一个简单的blob对象
1 | echo "test content" > test.txt |
hash-object命令先会给text.txt计算出文件头,然后将文件头加上文件本身内容计算出一个SHA-1哈希值 d67046 ,通过-w参数,git会将test.txt文件进行zlib压缩,生成一个blob对象,存入git仓库,最后再返回对应的SHA-1值。在Git中,该SHA-1值即为text.txt文件的索引。(如上面所示,我们可以使用 cat-file -p 命令查看索引 d67046 指向的blob对象的具体内容,cat-file -p 命令是Git查看文件的瑞士军刀,只要是Git对象都可以通过SHA-1值查看存储的对象内容)。我们可以进入到Git的仓库目录.git文件夹下,看看我们的这个文件的版本记录被转存到了哪里。
1 | find .git/objects -type f |
可以看到Git以SHA-1值的前两位作为文件目录,将blob对象存储在了.git/objects文件夹。那么一个文件的多个版本Git怎么存储呢?我们可以试验一下
1 | echo "text content version 2" > test.txt |
可以看到git将两个版本的test.txt文件分别进行了存储,而非增量的形式存在,这是Git的默认存储方式,松散存储。好处是不用追溯多个版本去还原一个文件的内容,但同时也会牺牲一定的存储空间,Git为了解决空间利用的问题,提供了文件gc的功能,但这不是重点,我们略过不谈。 有了上面的两个blob对象,我们其实就可以进行版本管理了,向下面这样,我们可以轻松的一个文件的两个版本上进行切换。
1 | git cat-file -p 2638ce0f549ff134a334e415c6e3a9fbc5ae2 > test.txt |
看,我们成功的将文件恢复至了第一个版本。
tree对象
好了,现在我们可以在Git仓库中管理一个文件的多个版本了,那么想要管理一个工作目录的历史版本,该怎么做?总不能一个一个的把工作目录下的文件加入到Git仓库吧?Git为我们提供了解决方案:tree对象。tree对象在Git管理中类似于linux下的目录的功能,其结构中包含指向一个或多个blob对象或者子tree对象的索引。类似如下的结构
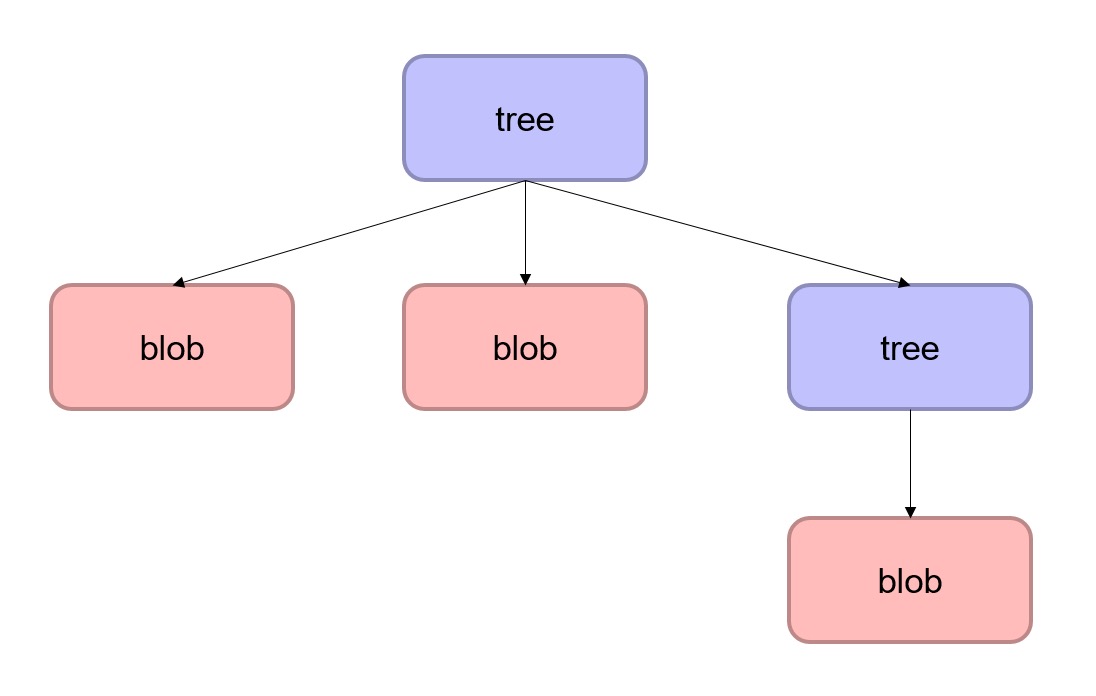
我们可以尝试一下手动创建一个tree对象。tree对象可以借助Git的缓冲区(index文件)进行创建。我们首先将文件的索引加入缓冲区,而后将缓冲区中的索引集合转化为tree对象。通过Git的update-index和write-tree 命令,我们可以轻松的做到这一点。
1 | git update-index --add test.txt |
我们将Git缓冲区中的所有索引以类似快照的形式生成了一个SHA-1值为 19600d 的tree对象,该tree对象即为此次缓冲区的历史版本。这里细心的同学会注意到,我们并没有对 test.txt 对象做 hash-object -w 操作,但是同样在objects目录下生成了 2638ce 对象。我们可做这样的猜想,Git的 update-index 命令在执行时,会先执行 hash-object命令,为文件生成SHA-1值,如果SHA-1值不存在于缓冲区,或者与现有缓冲区中的SHA-1值不同,则会先执行命令 hash-object -w操作,生成blob对象,然后再新增或者更新文件的索引至缓冲区。 我们再尝试增加一个文件验证一下。
1 | echo "new text" > new.txt |
这一次,我们在执行update-index -add 命令后,执行了 ls-files --stage 命令,该命令可以查看缓冲区中的索引情况。这里,我们看到在 update-indxe -add 命令之后,objects目录新生成了一个索引为 eee417 的blob对象,而后该索引被加入到缓冲区中。在执行 write-tree 命令后,我们看到生成的tree对象的内容即为缓冲区的一个快照。
有了tree对象,我们就可以方便的将整个项目的工作目录进行版本管理了。首先将整个工作目录的文件加入缓冲区(即加入索引),然后再通过缓冲区生成tree对象,这样就不用一个个的为项目中的文件使用 hash-object命令,添加版本控制了。但一个项目在迭代过程中,肯定会产生很多的tree对象,怎么组织这些tree对象,串联出一个项目的时间线(即历史信息)呢?怎么样能够随时在一个项目不同时期的版本上随意切换呢?Git为我们提供了一个很好的解决方案:commit对象。
commit对象
commit对象提供了一个更人性化的方式管理所有的tree对象,其包含的主要信息有:
- 指向顶层tree对象的指针
- 指向父亲commit对象的指针
- 提交时间戳
- 提交描述
每个commit对象必然携带一个tree对象,即一一对应。这样,commit对象就像是tree对象的一个“说明书”,提供了tree对象的提交时间和提交描述,最重要的是,提供了父亲tree对象的“说明书”的地址(即父亲commit对象指针)。这样零散的tree对象就通过commit对象,在时间线上被前后串联了起来。我们想要查看一个文件的历史版本,只需要在commit对象上追溯,找到这个文件相关的所有commit对象指向的tree对象,接着再找到所有tree对象中,该文件的索引值,就可以随意翻看这个文件的所有历史改动。
我们可以通过Git的 commit-tree 命令来模拟一下commit的串联。
我们先将我们刚才获取到的第一个tree对象 19600d 进行一次提交
1 | echo "first commit" | git commit-tree 19600deac4f0ab9b5fa0fc61c9ee03647cfe61ce |
这样我们得到了一个 d6da9c commit对象,继续将第二个tree对象进行提交,并指定 d6da9c 为其父commit
1 | echo "second commit" | git commit-tree 369fe222da08762cb4f02ddee8efc4637afbc5a2 -p d6da9c |
通过 git log 命令,我们发现,两个commit对象已经串联了起来,我们已经有了一个工作目录的历史版本记录,如下图所示。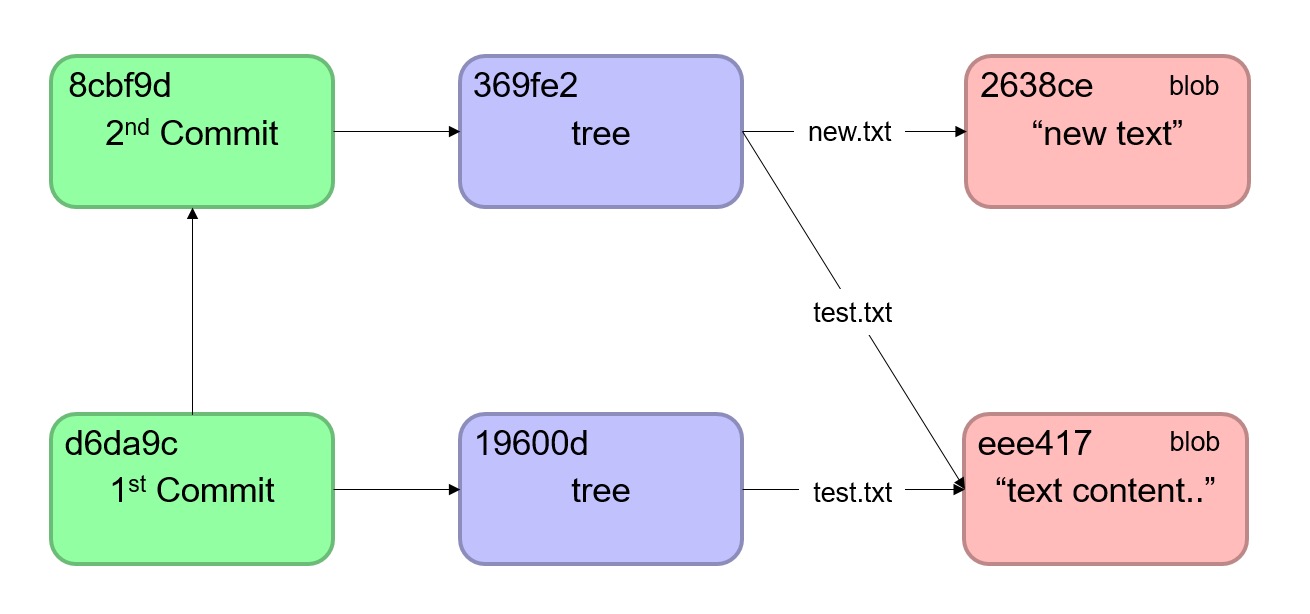
references
在日常的版本控制中,我们会发现,仅仅有commit对象还是不能满足我们的需求,为什么?因为SHA-1值实在太难记了。即使只需要记住最近的一个commit对象的SHA-1值也是很困难的,而且往往我们的需求不仅限于此。我们还会希望能够记录一些里程碑式的commit,便于提供给开发者或者使用者多个稳定的老版本和一个最新的开发版本。Git提供了一个更人性更便于记忆的方式:reference。reference相当于难于记忆的SHA-1哈希值的一个别名,我们可以给SHA-1哈希值起一个更易于记忆的名字。我们动手实验一下
1 | git update-ref refs/heads/master 8cbf9de25c7bf88fa3cb55718d90da9601162ed3 |
我们通过 git update-ref 命令创建了一个 master 引用,现在我们分别使用 master 引用和SHA-1哈希值查看一次log。
1 | git log --pretty=oneline master |
效果完全一样,还有一个有意思的地方,执行一下 git branch 命令看看
1 | git branch |
其实通过 git update-ref 命令,我们已经创建了一个 branch 。实际上,每当你执行 git branch (分支名称) 这样的命令,Git 基本上就是执行 update-ref 命令,把你现在所在分支中最后一次提交的 SHA-1 值,添加到你要创建的分支的引用。同样的原理也适用于 git tag 命令,区别仅是 branch 的引用存储在 refs/heads 而 tag 的引用存储在 refs/tags 。 现在的问题是,在上面执行命令时,我们指定了SHA-1值为 8cbf9d ,所以一切顺利。但是当你执行 git branch (分支名称) 这条命令的时候,如果你不知道最后一次提交的SHA-1值,该怎么办呢?
这里Git增加了一个比较特殊的引用:HEAD。可以观察一下HEAD文件的内容
1 | cat .git/HEAD |
可以发现HEAD文件,实际是一个指向引用的引用。Git将它设定为始终指向了当前工作目录的最后一次提交的 SHA-1 值。例如现在,HEAD指向了 master 引用,实际也就是指向了当前工作目录的最新一次commit:8cbf9d 。这样的做法,对于打出新的tag和branch来说非常方便,只需把HEAD指向的commit的SHA-1值添加到你要创建的 branch 或者 tag 的引用上即可。
最后,我们还有一类特殊的我们一带而过:remotes。这类引用指代了本地仓库关联的远程仓库的引用情况。如果你在进行团队协作可发,那么很可能你会使用到到remotes引用。
所以,全局的来看,Git的核心结构大致是如下这样的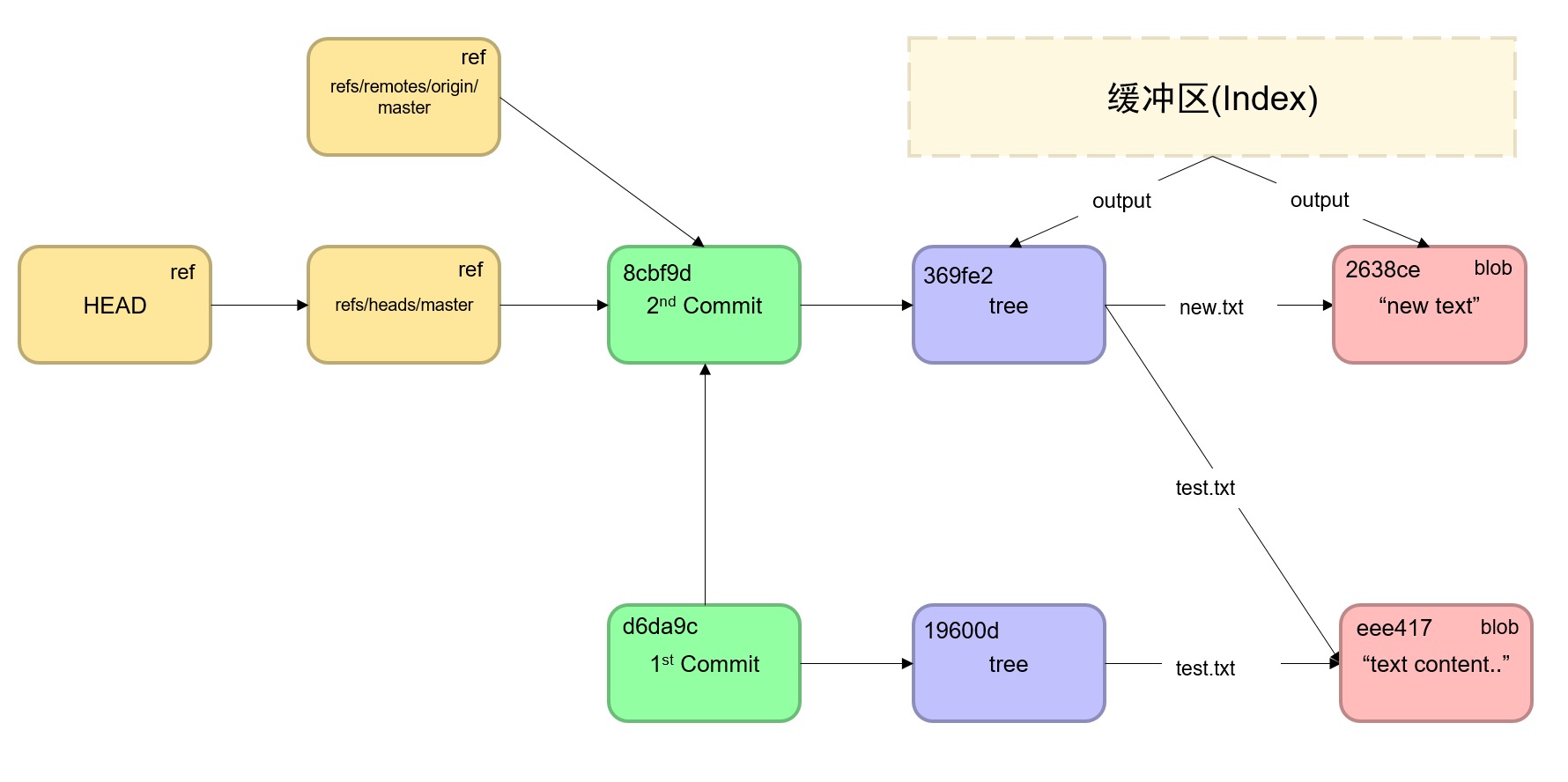
3. Git应用实战
到目前为止,我们描述了Git的内部对象、引用以及核心的设计思路,这基本上就是运行 git add 和 git commit 命令时 Git 进行的工作 ── 保存修改了的文件的 blob,更新索引,创建 tree 对象,最后创建 commit 对象,这些 commit 对象指向了顶层 tree 对象以及先前的 commit 对象。除 git add 和 git commit 之外,Git为了达到方便使用,分布式版本控制等目的,还贴心的为我们准备了很多语义清晰的高级命令,这里我们和工作场景结合起来为大家串联一下常用的工作命令。
Git基本命令
我们的工作,往往是从远程仓库上下载一份源代码开始的。 Git的远程仓库,本质上和本地仓库没有任何区别,只是为了能够达到团队合作的目的,团队成员间会达成协议,指定一个服务器上的Git仓库作为“核心”仓库,所有的开发人员都在这个“核心仓库”上交换代码,达到合作开发的目的。现在的一些代码托管平台,例如最出名的Github以及码市(coding.net),其最基础的服务就是为开发人员提供了远程的Git核心仓库,方便开发团队协同工作。
git clone
git clone 命令,用于从远程仓库克隆一份Git仓库至本地。这里假设远程仓库IP地址为10.3.4.127。我在10.3.4.127上发布了我的SSH key,所以以下的远程命令我都会以SSH协议的方式进行交互。现在我们动手从远程仓库上克隆我们的test项目。
1 | git clone git@10.3.4.127:ucarapi/test.git |
这样,test.git 仓库的所有对象以及引用都已同步至本地了。有一点不同的是,本地仓库的分支结构,并没有和我们预期的一样和远程仓库保持一致。我们的远程仓库上存在了两个分支,一个master一个newFeature。我们可以在本地仓库上通过 git branch 查看一下分支情况。
1 | git branch |
我们会发现,本地仓库里并没有newFeature分支。这时怎么回事呢?实际上git clone 将test仓库的所有对象信息都同步至了本地仓库。但是对于引用,Git对于远程仓库的引用做了特殊处理,在本地将这些引用信息保存为了remotes引用(前面有提到过)。为了解释这一点,我们可以看看git仓库中的情况。
1 | cat .git/packed-refs |
这里我们查看了.git/packed-refs信息,Git在进行远程仓库之间的信息交互时,为了节省流量会将对象和引用进行压缩,所以现在远程仓库中的引用信息被压缩在了packed-refs目录。我们看到,远程仓库的分支引用都完好的保存了下来。我们继续看一下分支引用所指向的commit的日志信息。
1 | git log a4a5b5526bf0dcec1cb1d34076d0f2b7ae60e49a |
可以看到 这个commit关联了3个commit,我们去Git仓库中看看这些commit是否存在。
1 | git verify-pack -v .git/objects/pack/pack-7868e822bc1d53620a707a9ed966be65cf75301e.idx |
前面说到了,Git在进行远程仓库同步时会压缩对象和引用以节省流量。这里对象都被压缩在了.git/objects/pack 包的.pack文件下,同时Git还为pack文件创建了索引文件,.idx文件。我们可以通过 git verify-pack 访问索引文件,来检查pack包中的文件内容。这里前四条索引恰好就是我们要找的4条commit记录,可见newFeature分支已经被我们完整的从远程仓库克隆了下来。为了证明这一点,我们可以断网尝试切换分支到newFeature。
1 | git branch |
我们并没有经过网络传输,在本地成功切换到了newFeature分支。
git branch & git checkout
在获得了一个本地仓库之后,接着我们希望创建一个属于自己的开发分支。通过 git branch 命令,我们可以创建一个属于我们自己的分支引用。通过 git checkout 命令,我们可以切换当前的HEAD引用至新创建的分支引用。
1 | git branch newFeature1 |
这样,我们就已经切换至最新的分支了。我们尝试在新分支上做点改动。
git add & git commit
我们可以使用 git add 命令将更改内容的索引更新至缓冲区,然后通过 git commit 命令将缓冲区中的索引输出成tree对象,生成commit对象,最后更新HEAD引用。
1 | echo "newFeature1" > newFeature1.txt |
我们成功在分支 newFeature1 上提交了改动。
git rm
我们有时会发现我们的提交了一些错误的或者是多余的文件,我们想要将这些文件从Git仓库彻底删除。这时当纯使用 rm 命令无法删除该文件,因为缓冲区内仍然保存着当前文件的索引,Git仓库中也仍保留着索引对应的blob对象,一旦我们执行 git checkout 删除的文件仍然会被还原出来。所以此时我们需要使用 git rm 命令将文件移除版本控制。
1 | rm newFeature1.txt |
这样,我们就成功删除了newFeature1.txt文件同时移除了该文件的版本控制。
git reset & git revert
有时我们在提交之后,想要回滚到提交之前的状态,这时我们可以使用 git reset 或者 git revert 命令。二者的区别是,git reset 仅是简单的将当前的HEAD指历史的commit,以达到回滚代码的目的;而 git revert 是通过在版本库中找到旧版本代码,还原至工作目录后,再次进行新的提交来达到回滚代码的目的。简单来说,git reset 的HEAD向历史提交方向移动,git revert 的HEAD继续向前移动。这里我们建议使用revert来处理回滚,这样我们能保持完整的版本记录,除非你非常确信,需要抛弃的commit谁都不需要知道。现在我们使用 git revert 回滚我们刚刚删除newFeature1.txt文件时的提交。
1 | git revert HEAD |
看,newFeature1.txt文件又回来了,同时log日志中多出了一次commit记录,标识了我们对本地Git仓库进行了一次revert操作。
git merge & git rebase
我们已经在newFeature1分支上进行了多次提交了。现在我们尝试将这些提交合并回master分支。这里我们可以使用 git merge 命令或者 git rebase 命令。git merge 命令将会将merge的结果重新生成一个commit对象,其parent指针同时指向master的最后一次提交和newFeature1的最后一次提交。这将产生一个梯形的提交树,如下图所示
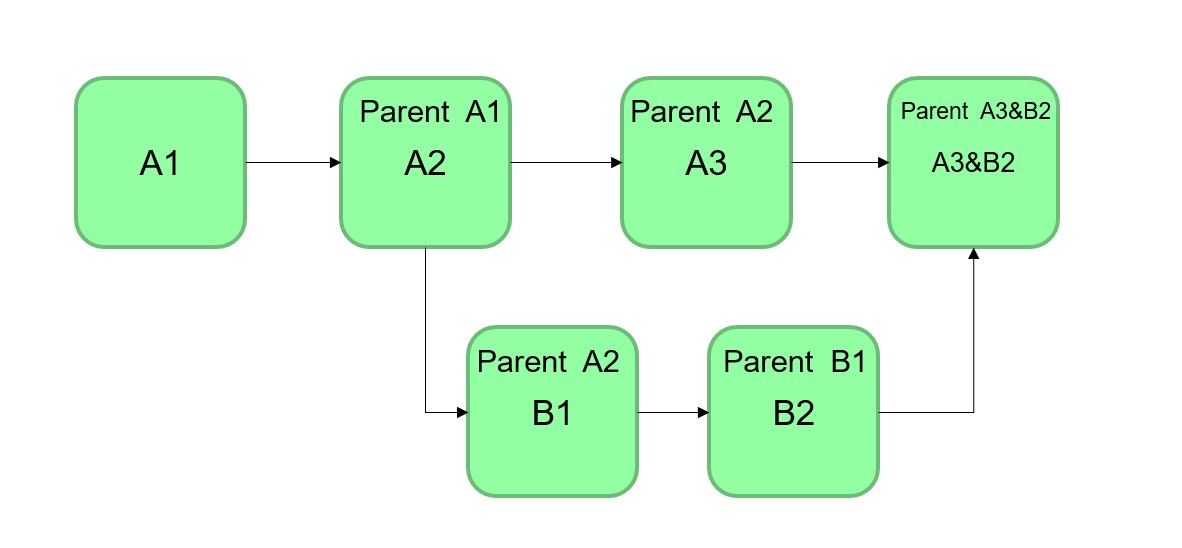
而 git rebase命令则是将master分支上打出newFeature1分支之后的commit记录全部挂起,然后将master分支重新定位至newFeature1分支的最后一次commit记录,最后再将挂起的commit记录依次添加到重新定位的commit记录之后。这样将产生一个直线形的提交树,就像下面这样
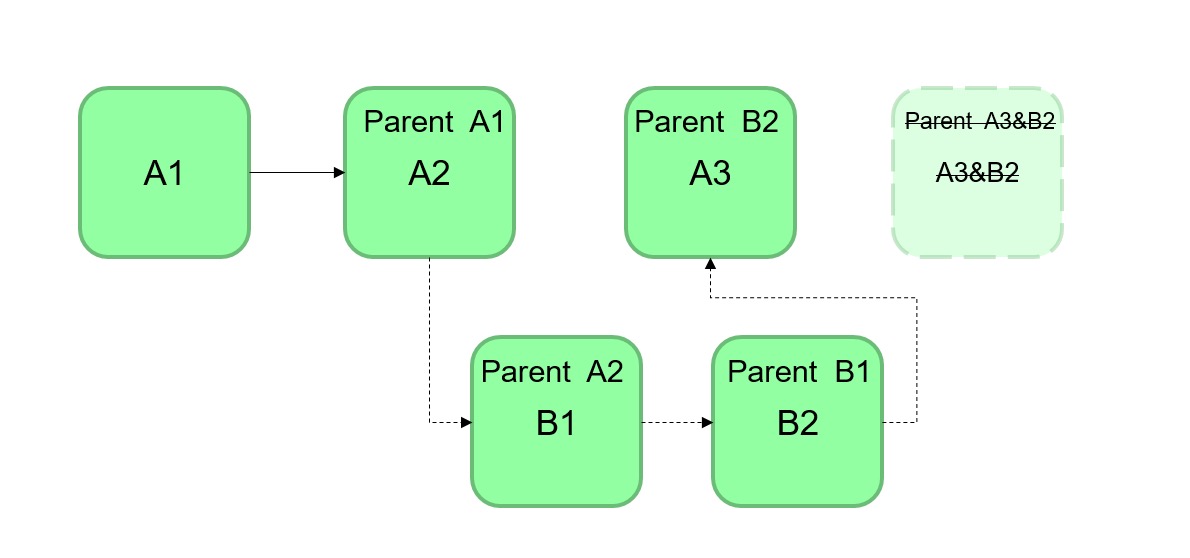
二者的特性可以从两个命令的语义上清晰的体现出来:merge将改变 融合 到当前的分支中从而产生新的提交,这样这个提交会像新生的提交一样,排列在提交记录的最前面;rebase不产生新的提交,而是将分支 重定向 到了新的提交树上,通过 改变历史 达到改变分支代码的效果。二者依其特性各有各自的适用场景:
git merge 适用于在开发完成后合并自己的代码至发布分支时使用,因为rebase不能很好的记录分支的合并的时间点——一旦rebase相当于就改变了历史,没法追溯是在哪个commit节点时进行的代码合并。从团队代码管理的角度来说,管理员会更希望看到发布分支上的每一个合并动作发生的时间,提交人,合并的代码内容等等。这些都是rebase没办法做到的。
git rebase 适用于在开发过程中同步别人的变更代码时使用,因为从时间上来看变更的代码在你开发的代码之前进入了远程仓库,同步时采用rebase不会产生多余的commit记录,且历史记录看上去也更加自然——因为变更的历史记录都会自然而然的排列在你的提交之前。
我们试着将我们的代码合并会master分支,既然是合并回master分支,那么我们使用 git merge 命令来完成这一操作。
1 | git checkout master |
可以看到我们产生了一个梯形的提交树(前面的提交记录太长未予展示),同时多了一个因为merge产生的commit 479b62 同时提示我们这个merge是因为两个commit记录 5fc6e12 和 e50edf7 融合产生的。
Git同步本地仓库
接下来我们准备推送本地代码至远程仓库,推送之前,我们需要同步一次本地仓库,以确保本地仓库代码为远程仓库的最新代码。
我们先查看一下我们需要推送的远程仓库地址是否正确,这一步可以使用 git remote -v 来查看。
1 | git remote -v |
可以看到 我们现在有一个叫做 origin 的远程仓库地址。现在我们从 origin 上抓取最新的代码至本地仓库。这里我们可以使用 git pull 命令 或者 git fetch 命令 。 二者的区别在于 git pull 命令会在将commit同步至本地仓库的同时,尝试在指定的分支上(或者默认追踪的分支上)进行git merge 操作。即 git pull 相当于 git fetch + git merge。这里我们为了节省操作步骤使用 git pull(命令的参数格式请自行查阅文档,此处不再详述)
1 | git pull origin master |
好了,我们成功同步了本地的代码。此时我们可以保证我们的代码在同步至远程分支时不再产生冲突。
Git推送本地代码
我们通过 git push 命令完成本地仓库代码发布至远程服务器的动作
1 | git push origin master |
这样我们成功的将代码发布至了远程仓库。
到此为止,我们就基本完成了开发工作过程中的整个生命周期。当然,在开发过程中还会遇到一些不在上述描述范围内的状况。例如代码冲突(在pull阶段可能发生),解决代码冲突的方式有很多,这里碍于篇幅原因,不再详述。
Git删除/创建/更新远程分支
有时,我们会需要删除远程上的分支,或者在远程上创建分支,或者推送代码至远程分支,这三个操作都可以使用git push 命令来完成。git push命令的格式是 git push <远程地址> <本地分支名>:<远程分支名> 。如果想执行删除操作,只需要推送往想删除的远程分支推送一个空分支即可,形如:git push origin :branch 。如果想执行创建远程分支的操作,只需要推送本地分支到远程的一个空分支即可,形如:git push origin branch。如果想更新远程分支,只需要推送本地分支到一个指定的远程分支即可,形如:git push origin branch:remoteBranch。
Git删除/推送远程tag
Git默认不会推送本地tag至远程仓库。如果想要对远程的tag执行删除,创建的操作,需要在git push 命令中显示申明。
推送一个tag至远程仓库:git push origin v1.0
推送所有tag至远程仓库: git push origin --tags
Git团队协作建议
综合Git应用实战中的描述,这里有两组命令容易混用:git reset & git revert 和 git merge & git rebase,这里针对这两个命令,提供了几个建议:
- 开发过程中,产生了新的提交时,慎用
git reset命令,因为这样会导致你的提交记录丢失,无法追溯。 - 不直接使用
pull命令,而使用fetch+rebase命令来同步别人新提交的代码。往往我们希望保持开发分支的历史记录能够按照开发提交的时间顺序排列在一条时间线上,fetch+rebase命令能够保证这一点,而直接使用pull命令将会使开发分支因为不同开发的之间的代码合并而变得混乱。 注意 ,这里需要确保,rebase的分支必须是你本地分支打出初始时跟踪的远程分支,一旦不在最初跟踪的分支上进行操作,一切将会变得混乱,具体原因可以参看Git分支的衍合一文。 - 合并开发完成的代码至发布分支(例如master)时,使用
merge --no-ff命令来保证提交历史记录的足够清晰。
GitIDE集成使用及插件介绍
这里我使用的是Macos系统下的IntellJ IDEA,所以主要介绍IDEA上的集成使用操作。
首先要使用Git,需要下载Git客户端,可以从官网下载。下载安装完成后,在IDEA中配置执行文件路径。
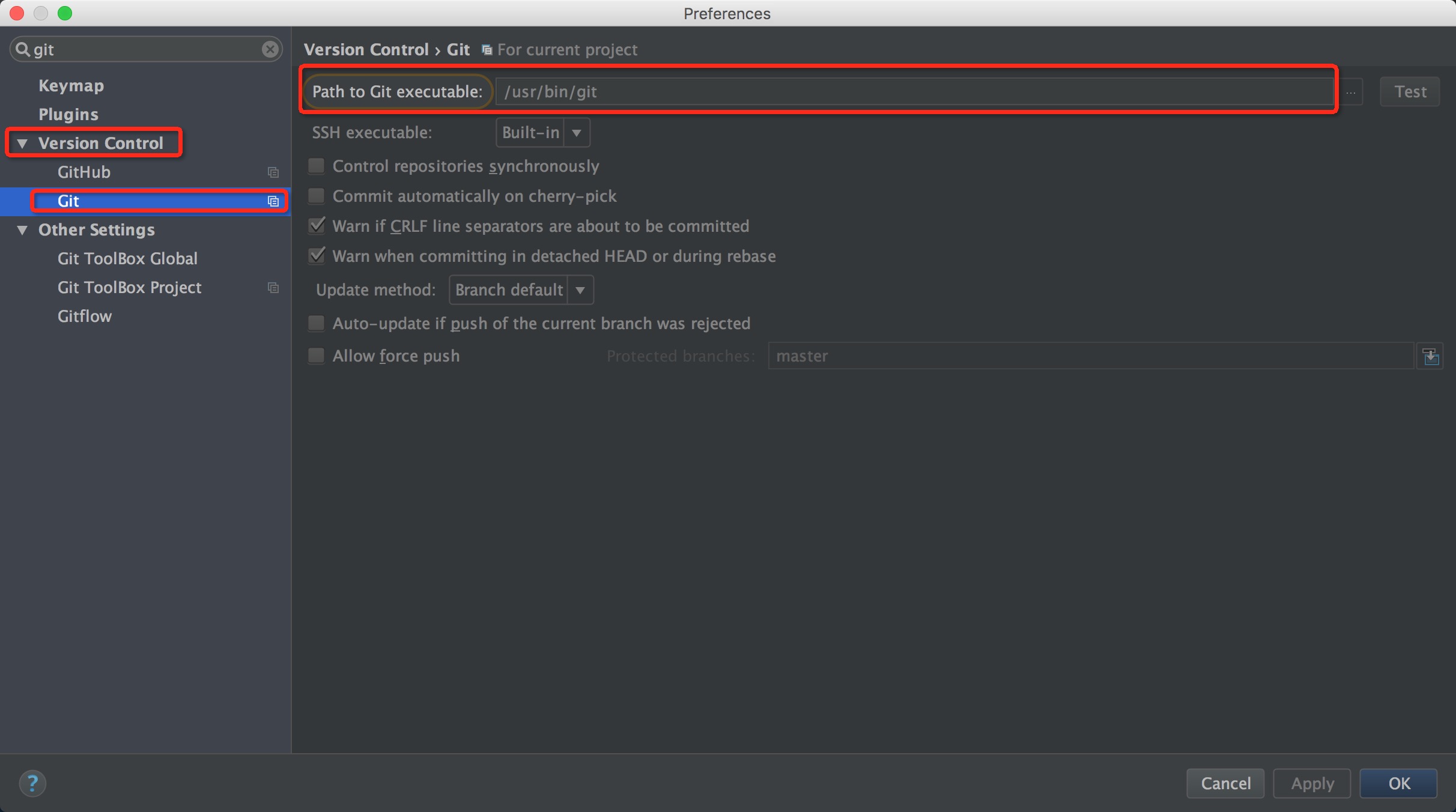
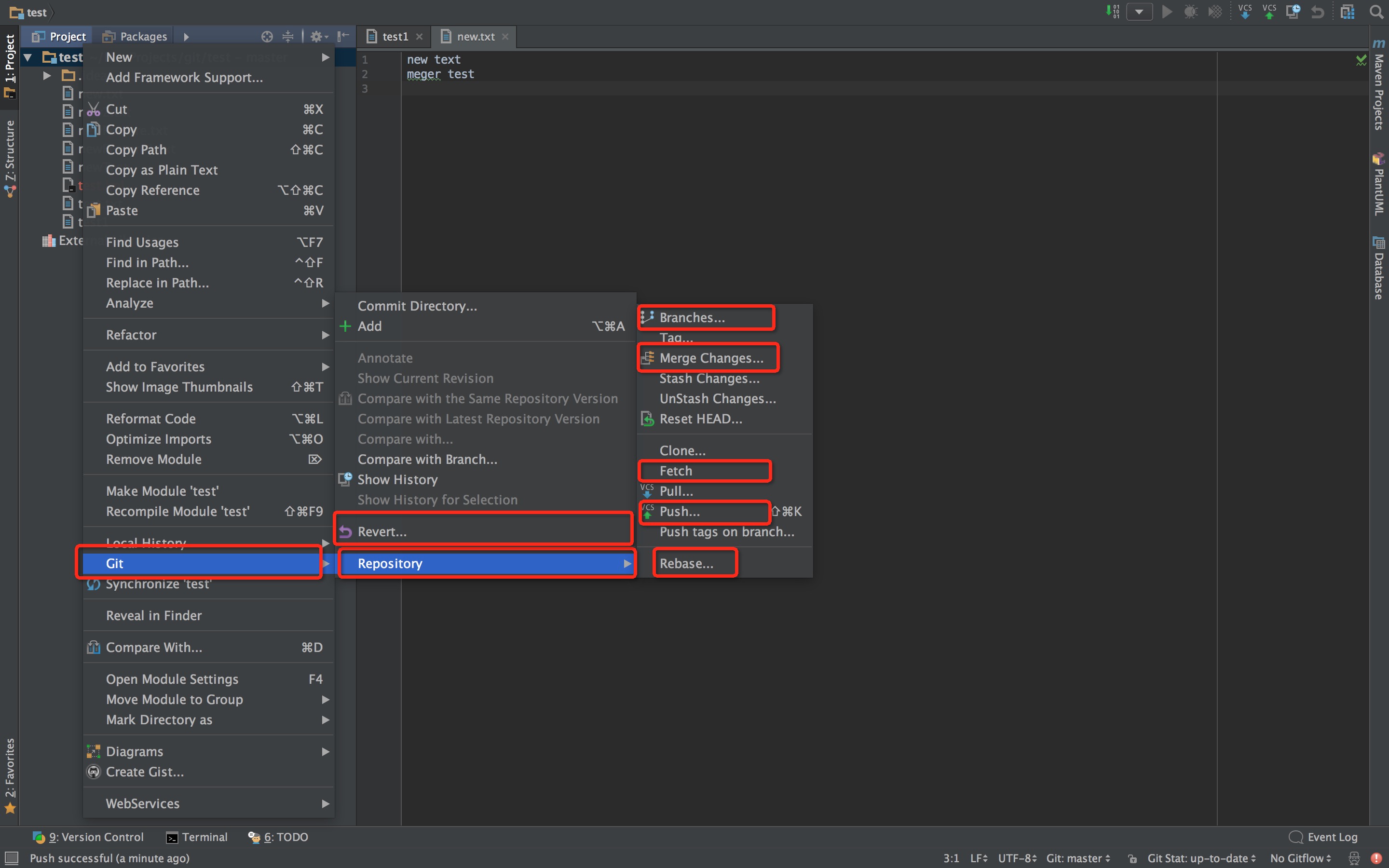
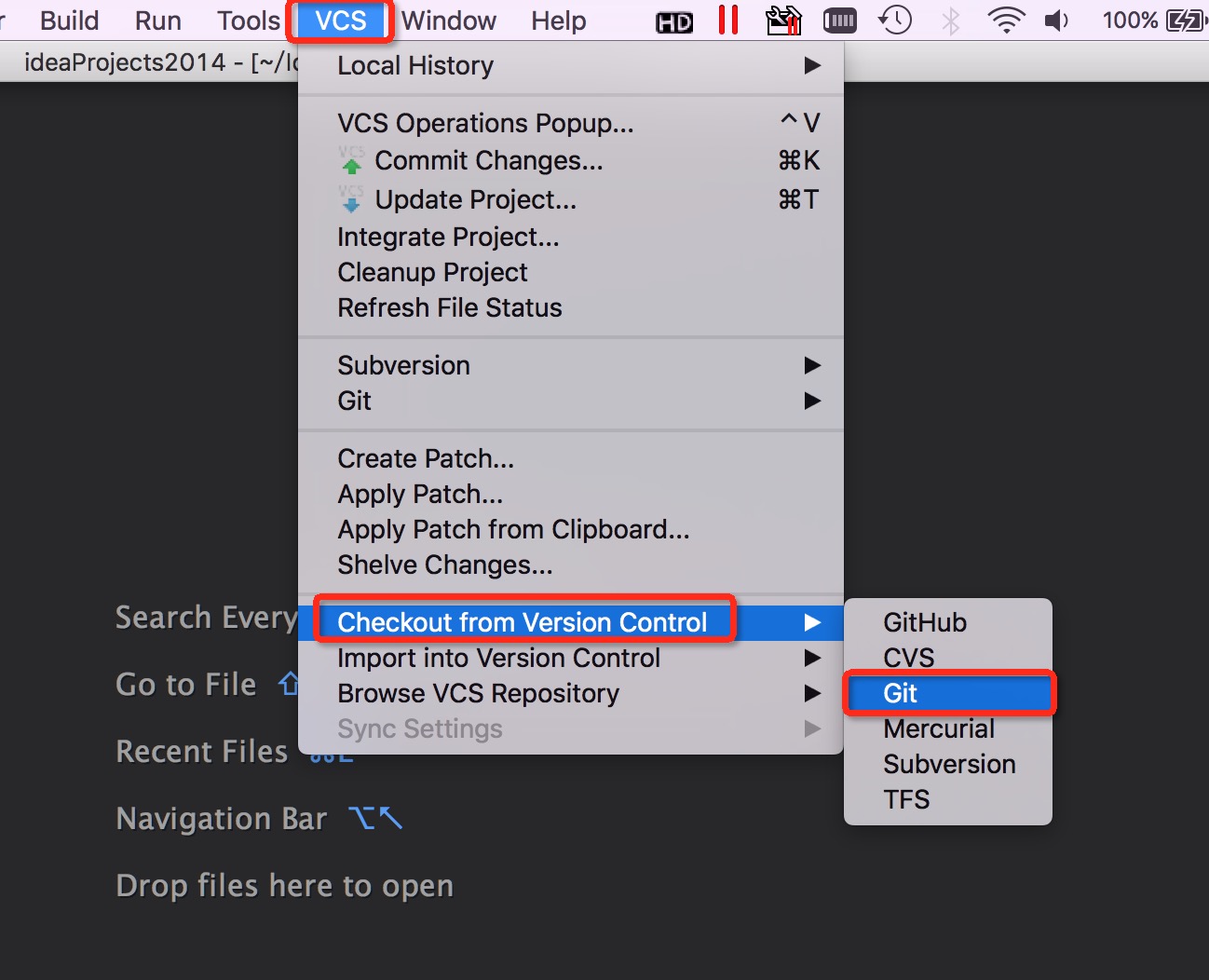
配置完成后,可以使用 VCS->Checkout from Version Control -> Git 菜单检出Git仓库。
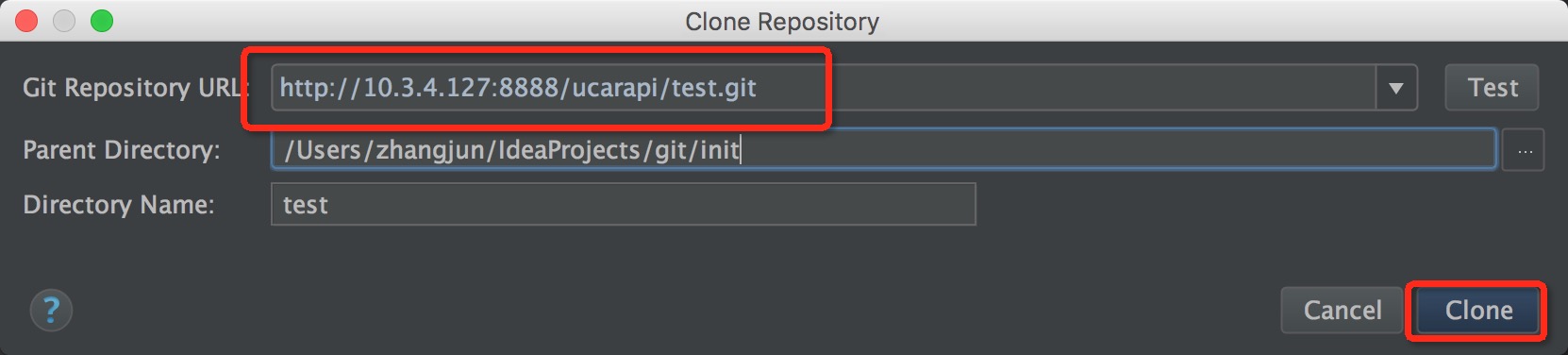
右键项目,你就可以开始通过IDEA,使用各种Git命令了。这里标记出来常用的几个命令。